AI Platform •
11 min read •January 16, 2026•204 views
Pgvector vs Pinecone: Choosing the Right Vector Database
Table of Contents
Choosing between Pgvector vs Pinecone is one of the most significant decisions an AI engineer will make. While one is a precision-engineered tool for high-dimensional math, the other is an organic extension of the world’s most trusted database.
Curiously, the word Pinecone isn’t just a tech brand; it’s a symbol of nature’s most efficient data storage. Just as a pine tree with pine cones protects its genetic data through the harshest seasons, your choice of a vector database determines how resilient and scalable your AI applications will be.
As an AI development company seeking to build future-proof solutions, understanding these structural foundations is paramount.
In this guide, we’ll explore the technical landscape of Pgvector and Pinecone, examining why the significance of pine cones, from their sacred geometry to their protective scales, actually offers a perfect metaphor for modern data architecture.
What are Pgvector and Pinecone?
Before choosing between Pgvector vs Pinecone, it is essential to understand the architectural philosophy behind each. Let’s start with the integrated approach, where vector search grows from an existing relational foundation.
Pgvector
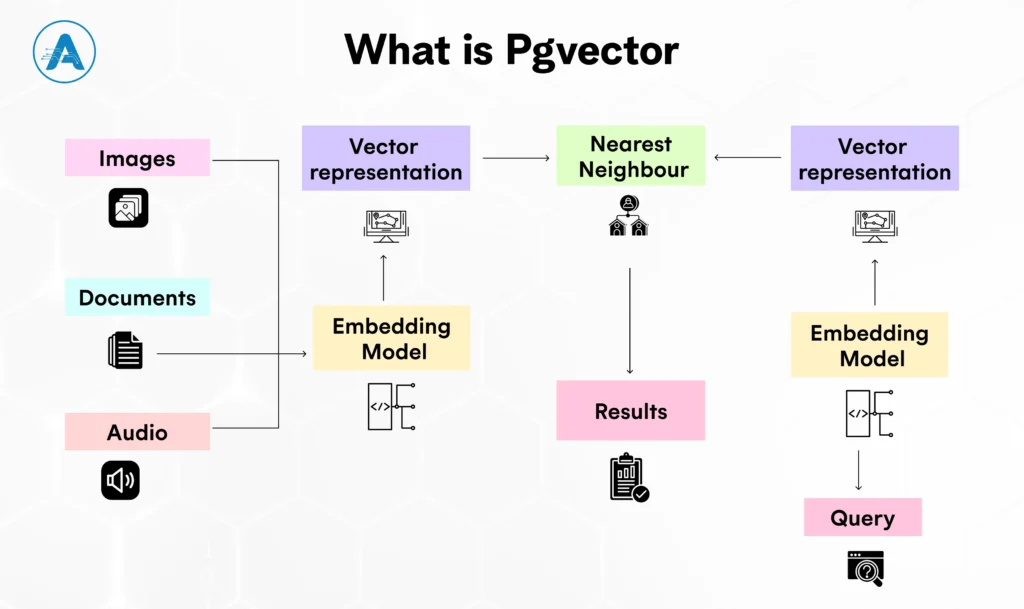
When comparing Pgvector vs Pinecone, Pgvector represents the self-managed, database-centric approach to vector search. Pgvector is an open-source vector extension for PostgreSQL that enables storing and querying embeddings directly within a PostgreSQL database.
The Concept: It is not a standalone database. Rather, it is an extension that provides PostgreSQL with the capability to read and write a new data type: the PostgreSQL vector.
Analysis: For an AI application developer, Pgvector offers a familiar SQL-first way to introduce vector search without redesigning the entire system architecture.
The Purpose: Its purpose is architectural simplicity. It enables you to conduct Nearest Neighbour searches in a familiar SQL syntax. It implies that you do not have to create a database that will store your AI features; you just expand your previous Postgres forest.
Best Use Cases
Relational RAG: Your search results are conditioned by some classical filters.
Cost-Efficiency: If you already have a Postgres instance, adding pgvector is virtually free in terms of licensing.
Data Integrity: Storing your vectors and metadata in a single place avoids the issue of data drift.
While Pgvector extends a familiar database, Pinecone takes a fundamentally different path, one built entirely around scale.
Pinecone
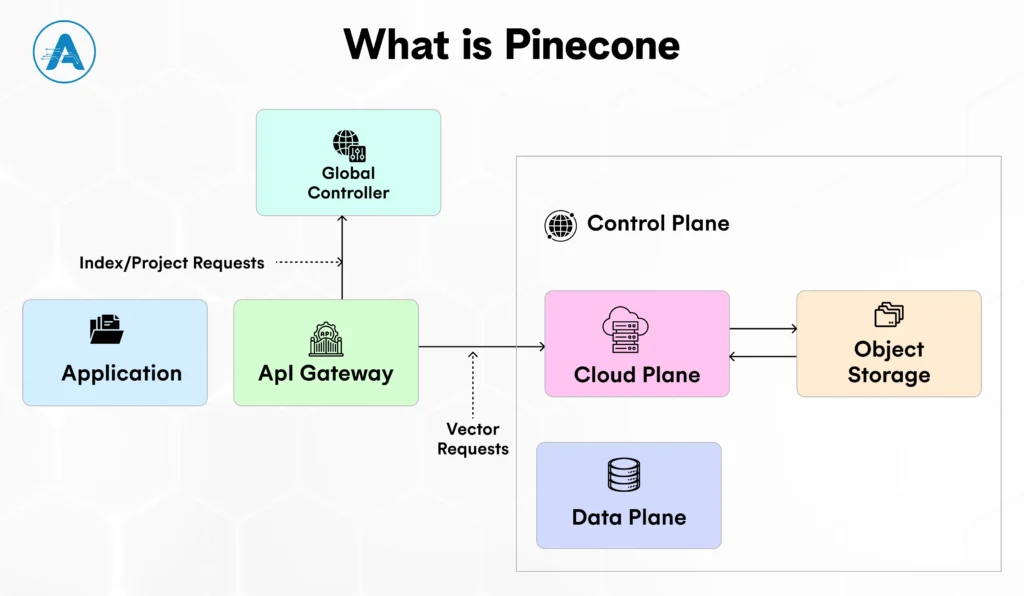
In the Pgvector vs Pinecone discussion, Pinecone represents the managed, purpose-built side of vector databases. Pinecone is a managed, full-fledged vector database, which is designed to store, index, and search high-dimensional embeddings in large scale, to be used with AI and machine learning applications.
The Concept: It is a Database-as-a-Service (DBaaS). You don’t install it on your own servers; you interact with it through an API.
The Anatomy: Much like the parts of a pine cone work together to protect and distribute seeds, Pinecone is organised into “Pods.” These pods are units of cloud resources that store your vector embeddings and handle the math required to search them.
The Purpose: It was meant to address the scaling wall. The Pinecone takes care of the infrastructure, memory, and indexing when you have a large tree of data in the form of billions of vectors, which you do not need to manage.
Best Use Cases
Extreme Scale: When you have a big pine cone scale dataset, think millions or billions of vectors, where a general database might struggle with memory.
Zero-Ops Speed: Ideal when the team requires going fast and does not have a full-time Database Administrator (DBA).
High-Performance Search: Applications where every millisecond counts, such as real-time facial recognition or instant recommendation engines.
Both approaches have been drawn quite clearly, and the actual comparison commences when we put them next to each other.
Pgvector vs Pinecone: Core Feature Differences Explained
When evaluating Pgvector vs Pinecone, the real differences show up in how each tool is built, scaled, and operated. Below is a clear, feature-by-feature breakdown to help you choose based on real-world needs, not hype.
Features
Pgvector
Pinecone
Core Architecture
PostgreSQL vector extension
Purpose-built vector database
Deployement
Self-hosted inside PostgreSQL
Fully managed cloud service
Setup
Requires DB setup and tuning
Minimal setup, ready to use
Scalability
Limited horizontal scaling
Designed for massive scale
Performance
Best for small–medium datasets
Optimised for large workloads
Query Method
SQL + vector similarity
API-based vector queries
Index Management
Manual index tuning
Automatic index optimisation
Data Control
Full data ownership
Managed with enterprise security
Cost Model
Lower infra cost, higher ops
Usage-based, lower ops effort
Architecture and performance matter, but cost is where many real-world decisions are ultimately made.
Cost Consideration for Pgvector vs Pinecone
When choosing between Pgvector vs Pinecone, the most significant factor for long-term sustainability isn’t just query speed, it’s the monthly bill. In the world of AI data, free seeds can grow into expensive forests, and managed luxury can quickly consume your development budget.
1. Pgvector Cost Advantage
For most developers, Pgvector is the clear winner for cost-efficiency. Because it is an open-source vector extension, the software itself costs nothing.
The Infrastructure Play: If you already run a PostgreSQL vector setup for your application, adding Pgvector is an incremental cost. You are simply utilising the CPU and RAM you are already paying for.
The “Hidden” Savings: You avoid the egress costs of moving data between your primary database and a third-party vector store. Keeping the parts of a pinecone in one Postgres instance reduces architectural complexity and network fees.
Self-Hosting Benchmarks: Recent industry data shows that a self-hosted Postgres instance with pgvectorscale on AWS EC2 can cost approximately $835/month, providing performance that rivals or beats Pinecone setups costing over $3,000/month.
2. Pinecone Pricing
Pinecone operates on a Database-as-a-Service (DBaaS) model, which means you are paying for the Zero-Ops convenience.
Pod-Based Pricing: Pinecone traditionally charges based on “Pods” units of cloud hardware. A single pod starts around $80–$120/month. However, to achieve high-speed queries (QPS) or high accuracy, you often need to add replicas, which doubles or triples that base cost instantly.
Serverless Scaling: Pinecone’s newer serverless offering is more budget-friendly for small projects, charging based on read/write units and storage ($0.33/GB/mo). This is a pine cone gift for prototypes, but for high-traffic production apps, these usage fees can scale aggressively and become less predictable than a flat-fee Postgres server.
Understanding cost is only half the equation; many teams still make avoidable mistakes during selection.
Common Mistakes When Selecting a Vector Database
Selecting a vector database is often where the hype meets the bill. Many teams stumble not because of technical incompetence, but because of a misalignment between their current needs and the tool’s intended use case.
Here are some common pitfalls to avoid:
1. Over-Engineering for Small Datasets:
Selecting a high-scale solution, such as Pinecone to an MVP with a small number of vectors. When your data can fit into the RAM of a standard server, a simple vector extension such as Pgvector is normally sufficient.
2. Creating Data Silos:
Selecting a specialised database and finding out afterwards that your vectors have been divided off of your metadata. This will compel you to write complicated code to synchronise your primary database and your vector store.
3. Ignoring Day 2 Operations:
Not considering the amount of effort needed to support the system. Pgvector is built where you have to handle your backups and index tuning, whereas Pinecone is built where you have to handle the monthly cost you are paying, and you are dependent on the API.
4. Underestimating Metadata Needs:
Making a decision using the speed of raw search as a criterion, and forgetting that the real-world RAG (Retrieval-Augmented Generation) means that the search must be heavily filtered. Pgvector is built to process such complicated SQL filters, and special tools might not do well.
5. Failing for the Purpose-Built Hype:
Assuming that because a database is marketed as AI-native, it is automatically better. As the PostgreSQL vector ecosystem has shown, adding vector capabilities to a battle-tested database often yields more reliable results than a brand-new specialised engine.
6. Budgeting Only for the Starting Price:
Not calculating how costs will scale. A cheap starter pod at Pinecone can easily grow into a large pine cone of a bill after you add replicas to it, because of high traffic or when you enlarge your vector size.
Avoiding these pitfalls becomes easier when you evaluate your needs through a clear decision framework.
How to Choose the Right Vector Database
Choosing the right vector database can define whether your AI system scales smoothly or becomes a bottleneck later. Teams comparing Pgvector vs Pinecone are usually at a critical decision point: moving from experimentation to production. Making the right choice early saves months of rework and unnecessary infrastructure cost.
This is often the stage where structured AI application development services help teams assess scale, cost, and long-term maintainability before locking in a vector database.
1. Role of Vecor Search
Start by clarifying how central vector search is to your product. Pgvector can be a feasible solution in case embeddings can accommodate the existing relational workflows. Provided that the core feature, such as semantic search or RAG, is powered by the vector search, then Pinecone is usually more risk-averse in the long-term.
2. Plan for Scarl and Growth
A lot of AI systems perform well during the initial stage and fail as the data increases. Pgvector is an application of controlled workloads, whereas Pinecone is built upon the concept of continuous scaling with equal performance.
3. Assess Operational Overhead
Self-managed databases require ongoing tuning, monitoring, and scaling decisions. Managed vector databases lessen this load, but provide service dependencies.
4. Evaluate Total Cost of Ownership
The infrastructure cost does not present the whole picture. All of these factors: engineering time, maintenance effort, and reliability have an impact on long-term ROI.
5. Align with Long-Term AI Strategy
Your vector database should support your future AI roadmap, not restrict it. Such capabilities as RAG, multi-tenant search, and real-time inference require varying architecture capabilities.
Once the trade-offs are clear, the final step is aligning your choice with long-term product and AI strategy.
Final Thought
The decision of Pgvector vs Pinecone is a question of the extent of scale, control, and operational simplicity that your AI system actually requires. Pgvector is a useful PostgreSQL vector and vector extension option that is suitable when teams desire to have AI functionality near their existing PostgreSQL stack and have a higher focus on flexibility and cost.
Pinecone is constructed around another reality in which search using vectors is infrastructure. Being a purpose-driven system, Pinecone reflects the significance of pine cones in nature: organised, sturdy, and able to grow big without human intervention.
There’s no universal winner in Pgvector vs Pinecone; only the database that best fits your current workload and long-term AI strategy.
Planning for AI Project
Get clarity on use cases, architecture, costs, and timelines with insights from 50+ real-world AI implementations.
1. What is the main difference between Pgvector and Pinecone?
The core difference in Pgvector vs Pinecone is architecture. Pgvector is a vector extension inside PostgreSQL, while Pinecone is a purpose-built, fully managed vector database designed for large-scale AI workloads.
2. Is Pgvector good enough for RAG applications?
Yes, Pgvector works well for RAG when vector search is combined with relational filters using a PostgreSQL vector setup. It’s especially effective for small to medium datasets and internal or early-stage production systems.
3. When should I choose Pinecone over Pgvector?
Choose Pinecone when vector search is a core feature, your dataset is expected to grow into millions or billions of vectors, or when you want minimal operational overhead with consistent low-latency performance.
4. Which is easier to maintain long-term?
Pgvector offers more control but requires ongoing database management. Pinecone is easier to maintain operationally since scaling, indexing, and availability are handled automatically.
5. What’s the safest way to decide between Pgvector vs Pinecone?
Evaluate your current workload, expected growth, team expertise, and long-term AI strategy. The right choice is the one that fits both today’s needs and tomorrow’s scale.
6. Does Pinecone support metadata filtering like SQL?
Yes, Pinecone supports metadata filtering, but it’s API-based. Pgvector has an advantage when complex SQL-style filters are required alongside vector similarity.
7. Which option is more cost-effective?
Pgvector is generally more cost-efficient at smaller scales since it’s an open-source vector extension. Pinecone’s managed model can become more expensive at scale, but it saves significant operational and engineering effort.
Design workflows are evolving at breakneck speed. AI Image Generators have officially transitioned from experimental “toys” to essential everyday assets for modern creatives. The…